学习Python过程中,第一个练手实例——爬取学院新闻网页,并正则匹配得新闻标题和链接。
抓包
一开始我是想在学院网的新闻动态页(固定url的页面)爬取所有的新闻title和link缓存起来,然后再用搜索的算法根据关键词匹配其中的新闻。后来觉得太麻烦了,搜索算法不好写,而且缓存那么多新闻并匹配也实在繁琐。
所以还是采取“正常”的做法,就是模拟浏览器动作——模仿操作者在学院网首页输入关键词,调用学院网后台的搜索程序,得到返回结果。所以我们得知道浏览器是怎么向服务器提交表单并接收返回的,这就是“抓包”。
一般浏览器都内置了“控制台”之类的调试工具,可以查看当前网络交互情况。比如在Chrome里,右键检查(Ctrl+Shift+I)就可以得到下面结果:
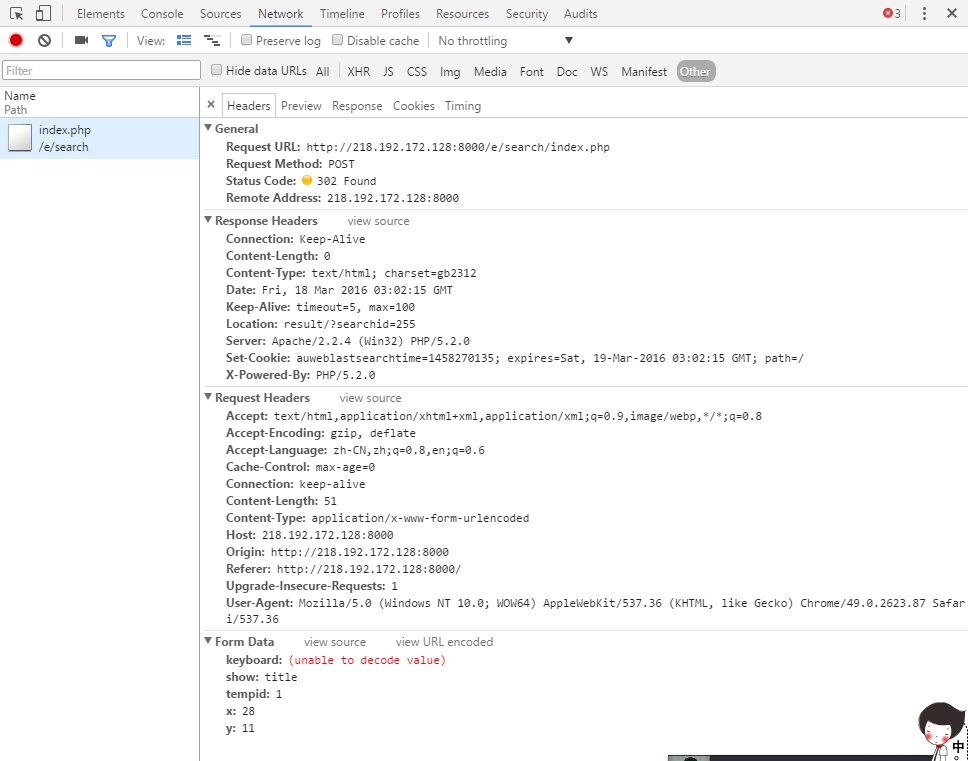
不过浏览器的控制台看不到学院网搜索程序的提交表单,所以用了Fiddler。这是一个http协议调试代理工具。打开Fiddler,然后在网页上操作,Fiddler监听到以下通讯:
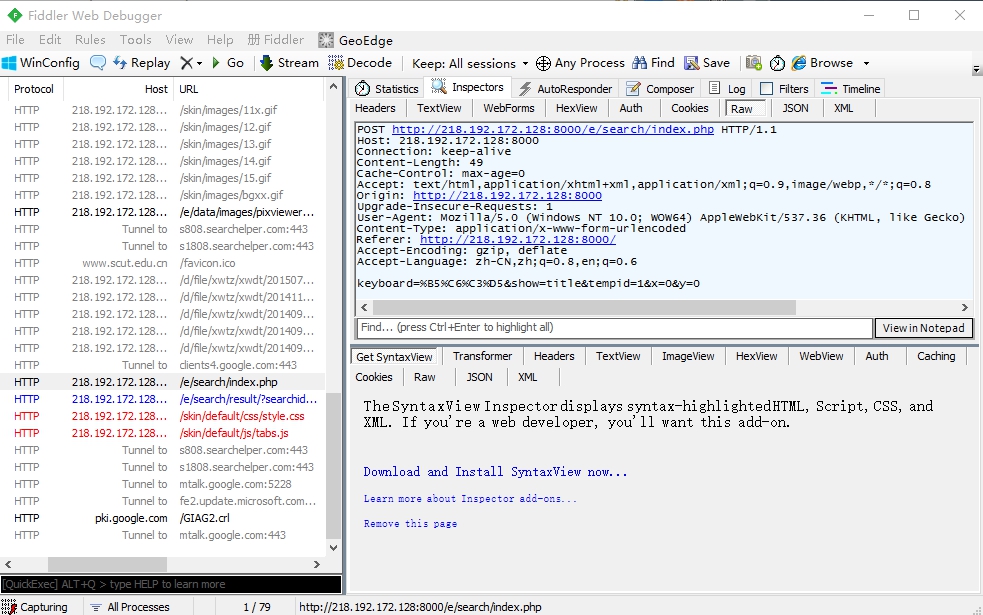
▲*右上窗口为网页请求,右下为网页响应*
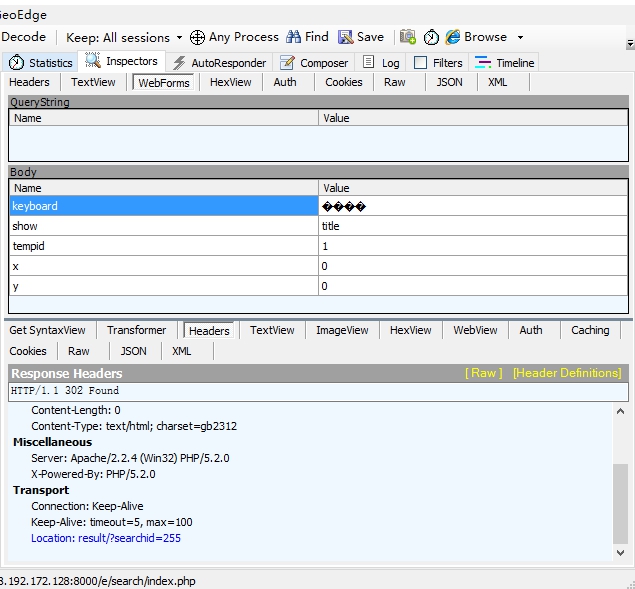
▲*当在搜索框输入“灯谜”,就向搜索程序/e/search/index.php提交了一个表单(字典)*
大致清楚浏览器背后的工作,就可以开始写程序了。
程序清单
引入模块
# -*- coding: utf-8 -*-
import urllib
import urllib.request
import urllib.parse
import re
import time
from bs4 import BeautifulSoupBeautifulSoup是一个Python的解释器,通过解析文档为用户提供导航、搜索、修改等功能。Python 3.x对应使用BeautifulSoup 4.3.2, Python 2.x使用BeautifulSoup 3.2.1。BS两个版本的函数基本功能差别不大,但命名相同!
获取目标网页
a = input("关键词:")
kb = a.encode('gb2312')
sm = '搜索'.encode('gb2312')
url = 'http://218.192.172.128:8000/e/search/index.php'
values = {'show': 'title', 'keyboard': kb, 'Submit22': sm}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.10240',
'Referer': 'http://218.192.172.128:8000/' ,
'Host': '218.192.172.128:8000',
'Content-Type': 'application/x-www-form-urlencoded'
}
data = urllib.parse.urlencode(values).encode()
#print(data)
req = urllib.request.Request(url, data, headers)
response = urllib.request.urlopen(req)
page = response.read()
#print(page.decode('gb2312'))
通过Fiddler的解析,我们从请求表头可以知道以gbk2312文本编码提交数据。提交表单内容包括键show、keyboard、Submitt及其值,然后进行urlencode,以POST方法提交。网站搜索程序接受表单经过处理重定向到目标网站http://218.192.172.128:8000/e/search/result/?searchid=255
抓取内容
soup = BeautifulSoup(page, "html.parser")
results = soup.find_all('h2', limit=2)
replyText = ''
pat = re.compile(r'xwtz(.*)html')
for result in results:
search = BeautifulSoup(str(result), "html.parser")
link = 'http://218.192.172.128:8000/' + re.search(pat, str(result)).group()
replyText += search.a.string + '\n' + link + '\n' + '----------\n'
#print (re.search(pat, str(result)).group())
print(replyText)
通过对网页html分析,知道想要的新闻稿title和link都放在<h2>里面,所以用soup.find_all('h2', limit=2)获取头两条新闻。并使用正则表达式去除一些标签,进行格式化后输出。
参考
尾巴
程序不复杂,代码压缩点也就不超过30行。但是这是自己写的第一个爬虫程序,过程中被gbk2013、UTF-8、ASCII以及Python版本兼容性折腾得不轻,所以就啰啰嗦嗦写了这篇博文。后来也将这个程序部署到了SAE,接入微信订阅号开发平台。多少有点用吧。