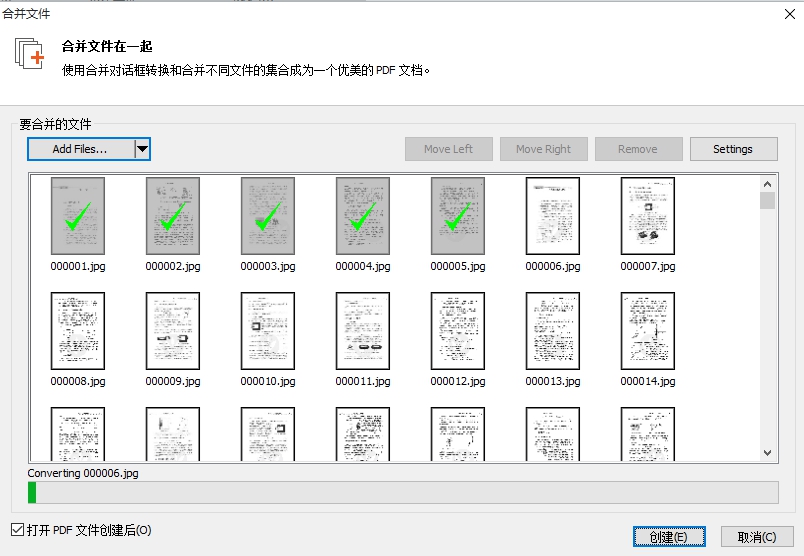
今天到图书馆找本电机与控制系统的书,刚好图书馆提供了这本书的电子版。华工的馆藏电子书提供全文浏览、截图以及最多4页的打印(pdf)。你想一下子下载整本pdf电子书那是没门的。要想离线查看整本电子书,要么每4页下载一次,要么每页另存jpg,都是糟心的事。所以可以写个小程序,把整本书‘下载’下来。
方案选择
华工图书馆不需要登录,就可以查询书籍,在书籍介绍页可以点进去相应的馆藏电子书。电子书是逐页jpg的方式展示的,静态资源,替换url最后的页码数就可以跳转到相应页。所以,不需要考虑header、cookies等问题,直接访问对应jpg链接就可以下载到图片了。

程序清单
urllib标准库
# -*- coding: utf-8 -*-
import urllib
import urllib.request
class BookSpider:
def __init__(self, bookURL, maxPage):
self.bookURL = bookURL
self.maxPage = maxPage
def saveImg(self, pageNum,):
imageURL = self.bookURL + r'&jid=/' + pageNum + r'.jpg&uf=ssr&zoom=0'
u = urllib.request.urlopen(imageURL)
data = u.read()
f = open(pageNum + r'.jpg', 'wb')
f.write(data)
f.close()
def loopSave(self):
for n in range(1, self.maxPage+1):
page = str(n).zfill(6)
self.saveImg(page)
#print(u'downloaded page %s' %page)
ec = BookSpider(r'http://202.38.232.20:8082/ss2jpg/ss2jpg.dll?did=a174&pid=2DF5922217715AAA7194BE7264BDED42059E8618EA5CFD1A7E4BD18652C0391E7B18FFFD83E68133094731F6088194B1DF33DC977271054AA7FB7926820C31E75214D342ADA63F5B95DA71EC3C6ED99A5B889ED2BCF72DE703653FB223A79E602284CC952E7C2806AE7612D2907FB552030D', 358)
ec.loopSave()
程序比较简单,注释就懒得写了。创建BookSpider类的时候提供两个参数,string类型的馆藏电子书的内容页链接的倒数第一个&号前面部分链接和int类型的页码数,然后执行loopSave()就可以了。
经测试,下载360页(80+M)的jpg,花了两分多钟(校园网网速还行)。
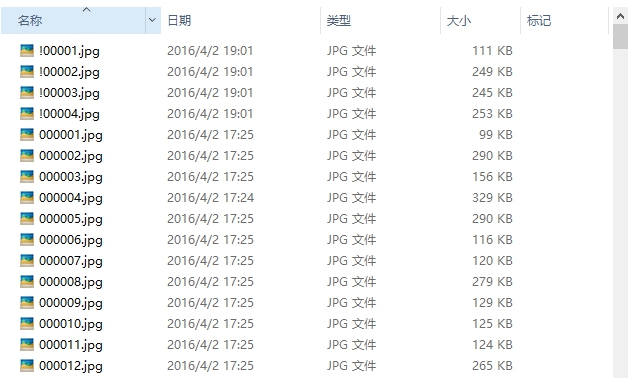
程序改进
上面程序执行是没问题,但是上面只是下载正文页jpg的。但是华工馆藏电子书是分封面页、书名页、版权页、前言页、目录页、正文页、附录页分别编页码的,对应链接也是分别编码。所以构造一个字典,储存不同类型页的链接。而且用条件打断配合while循环来判断是否到最后一页,不用自己输入页码数。What's more, 你可以自定义命名前缀。
# -*- coding: utf-8 -*-
# BookSpider_all.py
import urllib
import urllib.request
class BookSpider:
#书籍图片类型,包括封面页、书名页、版权页、前言页、目录页、正文页、附录页
#字典的value为[匹配链接,jpg命名前缀,页码位数]
imageType = {'cover':[r'&jid=/', 'cov', 3],
'bookname':[r'&jid=/bok', 'bok', 3],
'copyright':[r'&jid=/leg', 'leg', 3],
'foreword':[r'&jid=/fow', 'fow', 3],
'content':[r'&jid=/!', '!', 5],
'text':[r'&jid=/','', 6],
'appendix':[r'&jid=/att', 'att', 3]}
def __init__(self, bookURL):
self.bookURL = bookURL
def saveImg(self, img):
#循环访问图片链接
n = 1;
while True:
pageNum = str(n).zfill(int(img[2]))
imageURL = self.bookURL + img[0] + pageNum + r'.jpg&uf=ssr&zoom=0'
u = urllib.request.urlopen(imageURL)
data = u.read()
#当访问到一个空链接时依旧返回142字节的数据,通过判断byte大小来判断是否到页码尽头
if len(data) <= 142:
break
f = open(img[1] + pageNum + r'.jpg', 'wb')
f.write(data)
f.close()
print(u'downloaded page %s' %pageNum)
n += 1
def loopSave(self):
for item in self.imageType:
self.saveImg(self.imageType[item])
#你可以在下面括号内的''里面填入馆藏电子书的内容页的链接的倒数第一个&号前面部分链接
ec = BookSpider(r'http://202.38.232.20:8082/ss2jpg/ss2jpg.dll?did=a174&pid=2DF5922217715AAA7194BE7264BDED42059E8618EA5CFD1A7E4BD18652C0391E7B18FFFD83E68133094731F6088194B1DF33DC977271054AA7FB7926820C31E75214D342ADA63F5B95DA71EC3C6ED99A5B889ED2BCF72DE703653FB223A79E602284CC952E7C2806AE7612D2907FB552030D')
ec.loopSave()
jpg2pdf
下回来都是按照页码顺序命名的jpg,要转成pdf电子书可以用pdf编辑器。我用的是Nitro 9 Pro(强烈推荐,超级好用pdf阅读编辑器)。